一致性哈希算法
一致性哈希是一种哈希算法,主要用于分布式系统中数据的分片和负载均衡,一致性哈希算法解决了传统哈希算法在节点动态增减时可能导致数据迁移量过大的问题,能够提供更好的扩展性和性能。
普通的哈希算法
众所周知,哈希算法用于将字符串映射到固定长度的哈希值上,应用广泛,譬如Java中的HashMap,C++中的unordered_map,都是用到了哈希算法。
在分布式缓存中,数据被缓存到了不同的节点上,那么具体到一个数据的缓存或者访问,分布式缓存系统应该如何选择节点呢?
这里会遇到一个问题,即:
如果随机选择节点,那么比如第一次查询选择将数据缓存在A节点,第二次查询的时候有很大概率会选择其他缓存节点,那么则缓存失效,需要重新进行数据查询,这显然是不合理的!
另外,此举还会造成不同的节点缓存相同的数据,带来空间的浪费!
我们应该让相同的数据的缓存和查找落在同一个节点上,这样才可以充分发挥缓存带来的性能提升。
如何使得相同的数据的缓存和访问落在同一个节点上呢?
使用哈希算法可以很好地完成这样的工作——
现假设拥有5个节点,编号为0~4,可以首先将待查询key的信息映射到一个数字h上,可以有很多种方式完成这样的映射,最简单的,将key每个字符对应的ASCII码相加即可得到key对应的数字h,随后进行取模操作h%5,这样就把一个key映射到了一个固定的节点上,无论何时查询这个key都会访问同样的节点!
问题
上述方法虽实现了对于相同的key,在查询时稳定映射到同样的缓存节点,但是仍有较大缺陷。
在分布式系统中,支持节点动态扩容是很重要的功能,也就是常说的“弹性”。
上面的方法不可以很好地支持节点的动态扩容,如果现在需要增加一个节点,那么哈希算法将会变成h%6,这样,几乎所有数据所映射到的节点都发生了改变,而别的节点并没有对应的key的缓存,相当于在一瞬间,所有的缓存都失效了,引发缓存雪崩,所有的并发访问都涌向了后端数据库,这会给后端数据库带来骤然增大的压力甚至宕机。
一致性哈希算法就是用来解决普通哈希算法下分布式缓存系统无法实现动态容量更改的情况。
一致性哈希算法
哈希环
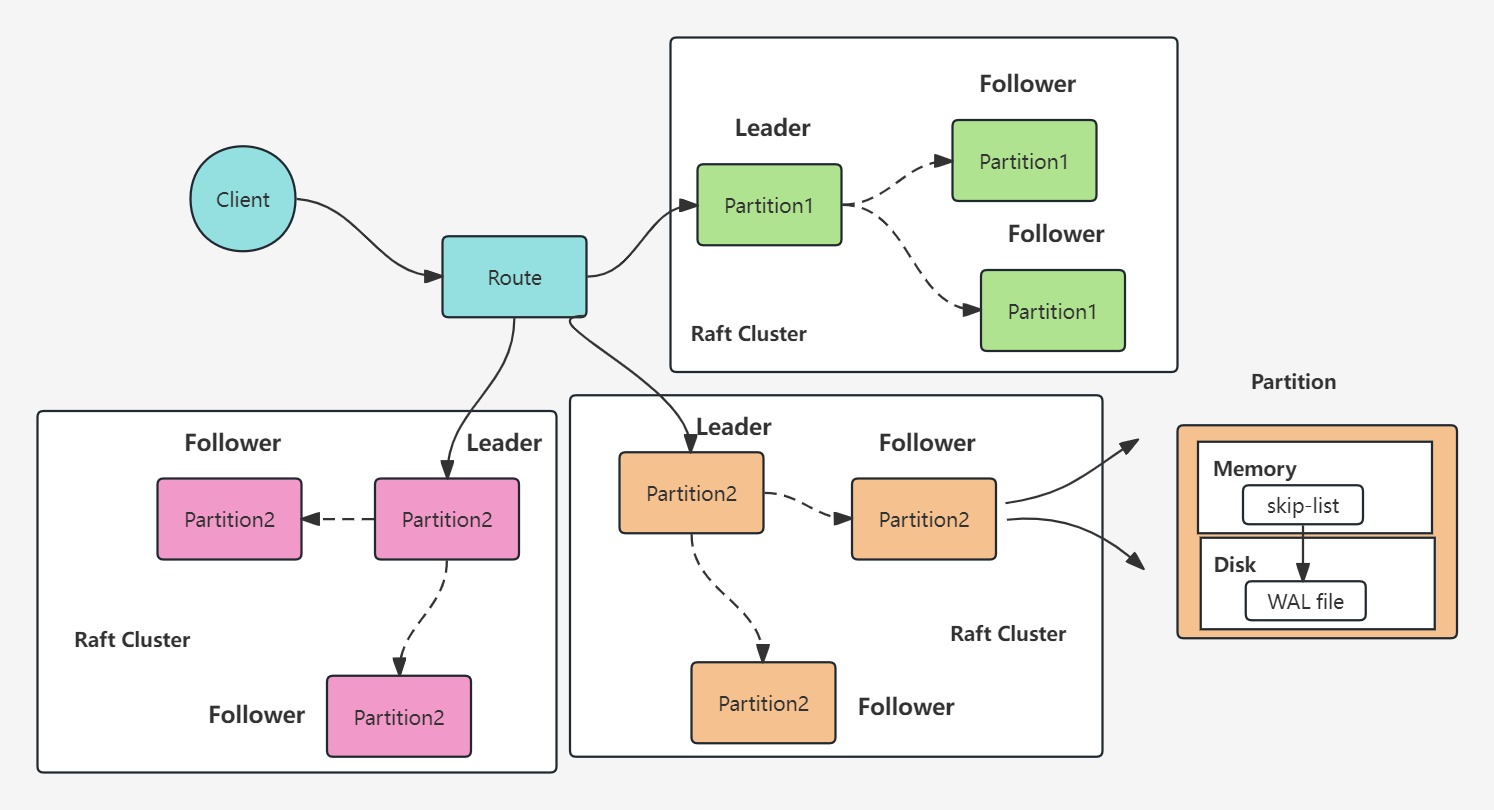
一致性哈希算法将数据或者节点映射到一个哈希环上,哈希环具有2^32个环空间,示意图如下:
一致性哈希算法也是取模算法,不过它是对2^32-1取模,任何一个数据都会被映射在哈希环上的固定位置。
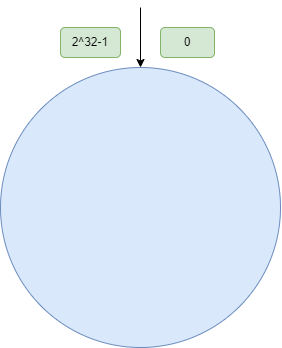
现假定已经有了三个节点,它们的信息通过哈希运算被映射在哈希环上:
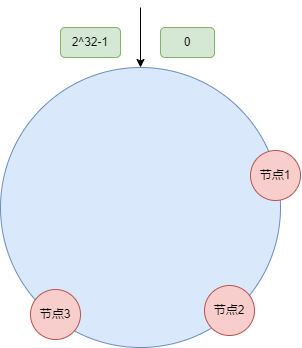
同时,缓存中的数据也分别会被映射在哈希环上:
对于数据,也就是key,它会在哈希环上顺时针找到下一个节点的哈希作为选择的节点,譬如上图,key2 key3都会被映射到节点2,key4 key5都会被映射到节点3,而key6 key7 key1都会被映射到节点1.
现假设增加一节点4:
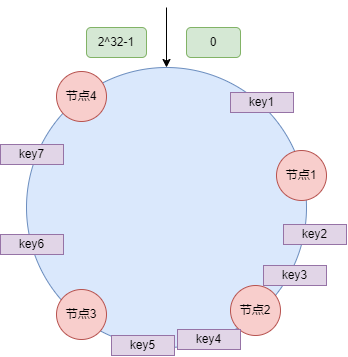
可以看到,新增节点4后,仅有key6 key7两个数据的映射节点发生了改变,而其余数据所对应的节点均未改变,这就很大程度上避免了大面积的缓存失效引发的缓存雪崩。
数据倾斜问题
如果哈希环之上节点数量较少,但是数据较多且在环上的分布较为集中,这样就会出现数据在节点之上分布严重不均匀的情况。
并且如果缓存数据非常多的某个节点A退出或者崩溃,那么原本映射在A节点的数据都会落在哈希环上的下一个节点(假定为B),导致映射到B的数据突然增多,如果之后B又退出或者宕机……以此类推,数据分布不均匀可能会导致大批缓存同时失效,从而引发缓存雪崩。
解决方法是设置一些虚拟节点,并把虚拟节点同样映射到哈希环上,数据沿着哈希环顺时针寻找时,如果找到的是虚拟节点,最终会映射到真实节点上,虚拟节点数量较多,从而避免了大多数数据都映射到同一个节点的情况,实现了负载均衡。